
contingency_table result
distractors fail pass
no 8 7
yes 0 7For Lyra-the-air-scenter and me, container searches aren’t a strong suit. They often feel like a somber, restrictive multiple-choice exam when we’re actually yearning for the thrill of a boundless, exploratory treasure hunt. We get by as best we can. If you don’t eat your meat, you can’t have any pudding.
Over the years, Lyra has patiently indulged me as I probe different angles from which to refine our container search training and performance. Along the way we have both learned a new skill or two. And I have gained new insights – about contained odor, how odor travels through and around different arrangements of containers as it “un-contains” itself, dog arousal when working near containers, handling that helps rather than hurts and much more.

At the end of 2023, I realized I was sitting on 22 fairly well documented observations of our performance in container search tests. These were at official trials or mock trials, so true tests (not training runs) and in all cases the hide locations were unknown to me.
I was curious to explore this mini dataset as a whole. I wondered if any patterns might emerge from looking through this slightly bigger-picture view rather than focusing on the specifics of any single individual container search.
Or maybe the exploration would help me realize that there weren’t any such patterns or findings of note; I was prepared for that too.

The 22 container search tests are visualized in the cards below. The solitary legend card on the left explains how to interpret the symbols encountered in the search cards below. Torn cards indicate searches with errors. Orange borders indicate searches with intentional distractors.







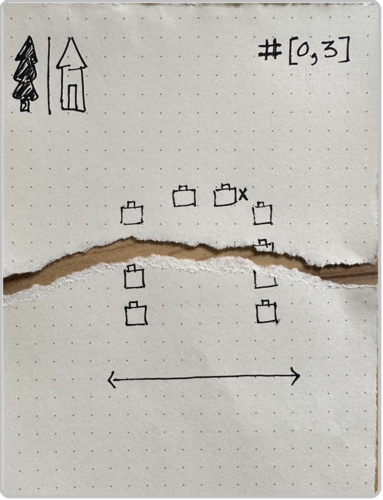







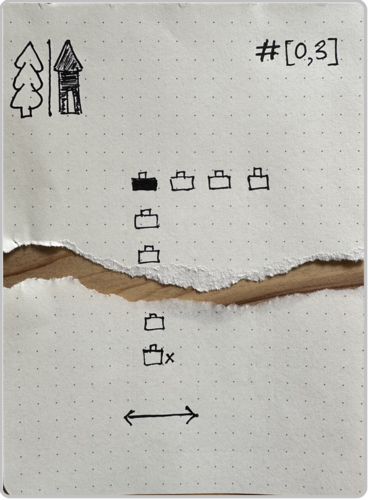



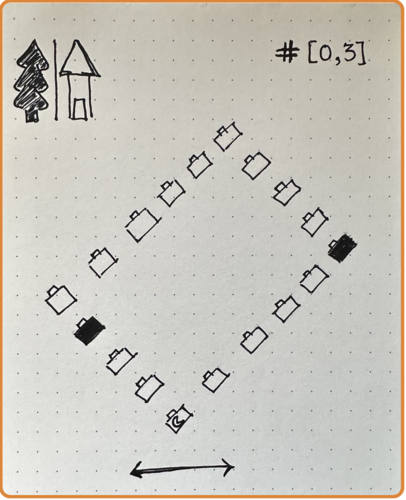


I meandered down a few different paths that led to uninteresting destinations. Was our performance improving or degrading over time? Answer: Neither; there was no apparent trend in either direction. Did we err more on the side of false alerts, or missed hides? Answer: Neither; amongst the tests we failed, the proportion of these two error types was fairly even. I’ve always felt that she enjoys working outdoors rather than indoors; was our container search performance better in outdoor locations as compared to indoor locations? Answer: Not really, and the opposite isn’t true either. The material of the containers, plastic vs. cardboard, was that relevant to our success? Answer: No significant relationship discovered, though maybe cardboard-only searches are a tiny bit harder. What about distractors? How badly were they throwing us off our game? Answer: Now wait a minute, we may be on to something!
There appears to be a relationship between our Pass/Fail result and the presence of intentional distractors. This isn’t just anecdotal, or driven by random chance. Rather the association looks to be statistically significant (jump to Section 6 if you’d like to review the math first). And here’s the kicker, the direction of the association is opposite to what I would have expected! It turns out that:
Lyra performs better (not worse!) in container searches that include intentional distractors in some of the cold containers. The difference in performance between the distractor vs. non-distractor cases is statistically significant.
I have been wondering why this unexpected relationship between performance and distractors holds true for this dog! And this really is about her alone and not us as a team as these were all tests in which I didn’t know if distractors were present, so there couldn’t have been any subconscious or subtle difference between how I handled the searches with the distractors and the ones without.
Some wild ideas that come to mind:
Tricky Question Select ONE favorite activity:
[x] Catching flying meatballs
[?] Digging for voles
[?] Scent rolling in goose poo
No-brainer Question Select ONE favorite activity:
[x] Catching flying meatballs
[ ] Visiting the vet
[ ] Having mats in fur combed out
I am not qualified in neuroscience, chemistry, or being dog, so conjecture is where these thoughts and ideas will remain. But this exploration gives me some direction for our future container search training.
I might focus more on container searches without any distractors as it seems that for Lyra, mastering the skills uniquely needed in these distraction-free searches is crucial. For the searches with distractors, I might systematically vary the balance between food and toys and low and high value distractors to further understand how broad or generalized this band of “distractors that help” really is for her. Once I know the band I might be able to modify it in some way to our advantage. I might experiment with tweaking the distractor + target odor picture that she is proficient at while playfully pushing the boundaries for new learning, e.g. conduct a container search without any distractors inside the containers but in an active kitchen area, or by a food garbage area.

Whether we make measurable improvements in our performance through all this will have to be seen. But the path this way promises to be delightful and engaging. Silly little dog experiments with my willing partner. Profound little experiments in the quest to vicariously understand her reality, her Umwelt.
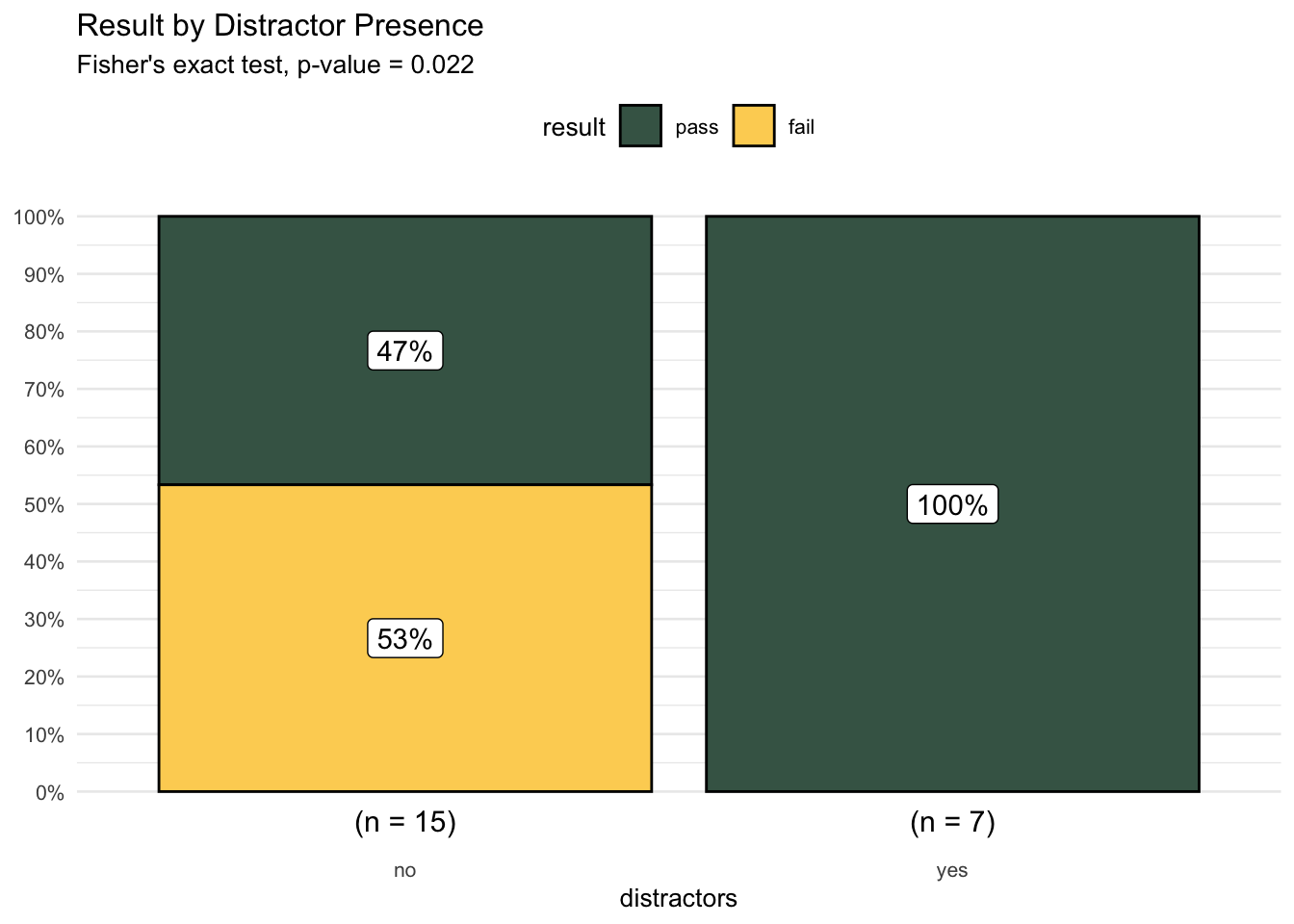
Observed Frequencies
Of the 22 searches, we passed 14 and failed 8. None of the searches that we failed had distractors. The contingency table of the frequency distribution of these two variables (result and distractors)looks like this:
contingency_table result
distractors fail pass
no 8 7
yes 0 7Testing for Independence
Is this seemingly extreme frequency distribution seen in the contingency table above really rare or is it actually fairly close to the expected counts that would occur if result and distractors were independent variables? Since the sample size is small, I’ve used the Fisher’s exact test of independence. The null hypothesis in this case is that the variables are independent. We will reject the null hypothesis, i.e. conclude that the variables are independent, if the p-value is less than the significance level of 5%.
fisher.test(contingency_table)
Fisher's Exact Test for Count Data
data: contingency_table
p-value = 0.02247
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
1.090835 Inf
sample estimates:
odds ratio
Inf Conclusion
The proportion of failed tests is higher among searches without distractors (53%) than among searches with distractors (0%). Based on the p-value of 0.02247 from Fisher’s exact test for independence, we reject the null hypothesis, concluding that result and distractors are not independent.
Thoughts on this post? Reply by email.